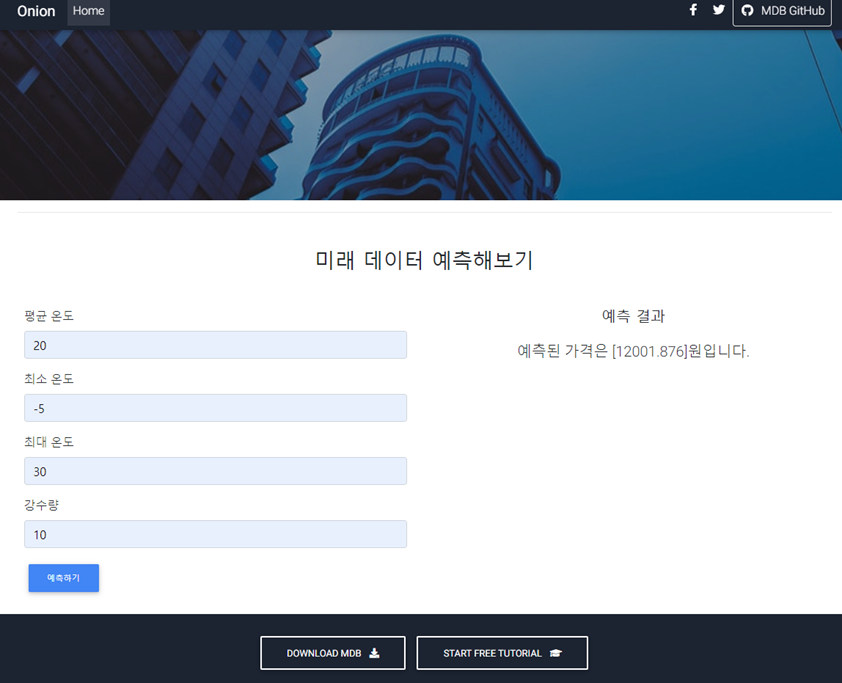
1. 소스코드 (일부)
1) jinja 변수 사용 부분
server.py에서 가져온 jinja2 데이터를 for문을 통해 보여줌 (소스코드 4, 6, 8)
jinja2 : 변수로 사용시 {{ data명 }}
for문 사용시 시작지점 - {% for문 입력 %}, 마지막지점 - {% endfor %}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<div class="v_left">
<div class="front">
<div class="fadeOut owl-carousel">
{% for i in range(1,len_s-1) %}
<div class="item">
<h6>{{ s_data[i-1][0] }}<br></h6>
</div>
{% endfor %}
</div>
</div>
</div>
<div class="v_center">
<div class="realcenter">
<div class="fadeOut owl-carousel" id="block-2">
{% for i in range(1,len_s-1) %}
<div class="item">
<h3 style="color: black;">{{ s_data[i][0] }}</h3>
<h6 style="color: black;">{{ s_data[i][1] }}<br></h6>
<h6 style="color: black;">{{ s_data[i][2] }}<br></h6>
<h6 style="color: black;">{{ s_data[i][3] }}<br></h6>
</div>
{% endfor %}
</div>
</div>
</div>
|
cs |
2) owl carousel 플러그인 사용 (JQuery)
웹 화면은 슬라이드 형태로 넘어가기 위해 owl carousel 플러그인을 활용하여 개발|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<script>
jQuery(document).ready(function($) {
$('.fadeOut').owlCarousel({
items: 1,
loop: true,
autoplay: true,
autoplayTimeout: 8000,
smartSpeed: 0,
animateOut: 'fadeOut',
animateIn: 'fadeIn',
nav: false,
dots: false
});
});
</script>
|
cs |
3) 스케줄링을 위한 refresh
crontab으로 시스템 업데이트 후에 웹에 적용하기 위하여 refresh해줌
content는 86400S를 의미함 (하루에 한번 refresh함)
|
1
|
<meta http-equiv="refresh" content="86400">
|
cs |
'웹 > Flask' 카테고리의 다른 글
| [Flask] API를 연동한 Flask 웹서비스 - AWS (0) | 2021.05.04 |
|---|---|
| [Flask] API를 연동한 Flask 웹서비스 - crontab (0) | 2021.04.29 |
| [Flask] API를 연동한 Flask 웹서비스 - crawling (0) | 2021.04.29 |
| [Flask] API를 연동한 Flask 웹서비스 - 구조 (0) | 2021.04.29 |
| [Flask] 선형회귀를 활용한 양파가격 예측 (2) | 2021.01.08 |