- 이 블로그 내의 Flask 내용 일부분은 YouTube 동빈나, '선형회귀를 활용한 배추 가격 예측 AI 개발' 강의를 요약 및 참고한 것입니다.
- 제가 이해한 대로 정리한 내용이기에 본문의 내용과 상이할 수 있습니다.
기상청 데이터를 활용한 양파가격 예측
1. 사용 프로그래밍 언어
분석 - Python ( tensorflow v 2.3.1)
웹 - Flask html js css ...
2. 데이터
기간 : 2010.01.01 ~ 2017.12.31
기상청 데이터 - 평균 풍속, 최저 기온, 최고 기온, 강수량
양파가격 데이터 - 양파 평균 가격 데이터 (크롤링)
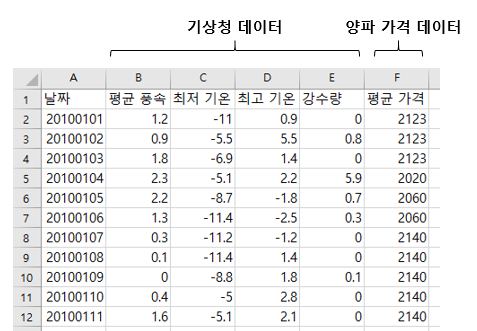
3. 시스템 구성도
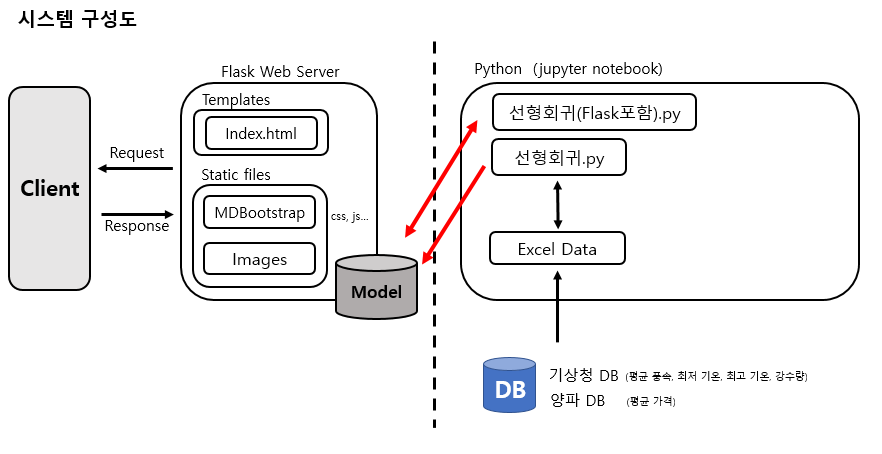
4. 파일 구조

5. 소스코드
(1) 처음 모델 만들기 위한 python 소스코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
import tensorflow.compat.v1 as tf
import numpy as np
import pandas as pd
from pandas.io.parsers import read_csv
#모델 초기화
model = tf.compat.v1.global_variables_initializer()
# 데이터 불러오기
data = pd.read_csv('data.csv', sep =',', encoding='latin1')
# 행렬 형태로 데이터 담기
xy = np.array(data, dtype=np.float32)
x_data= xy[:, 1:-1] #오른쪽 빼고 다 가져오기
y_data= xy[:, [-1]] #가장 오른쪽만 가져오기
tf.__version__ #tensorflow 버전 확인
tf.compat.v1.disable_eager_execution()
# (version1)session 정의 후 run 수행하는 과정 -> (version2)바로 실행
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 4])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([4,1]),name="weight") #가중치
b = tf.Variable(tf.random_normal([1]),name="bias") #bias 값
# 선형회귀 (행렬의 곱)
hypothesis = tf.matmul(X, W) + b
# 비용 함수 정의
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# 최적화 함수 사용 , 학습률 0.000005 ( 학습률을 적절히 정하는게 중요)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.000005)
train = optimizer.minimize(cost) #train 시작
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 학습 시작
for step in range(100001):
cost_, hypo_, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
#학습 모델 저장
saver = tf.train.Saver()
save_path = saver.save(sess, "./save.cpkt")
print("학습 모델 저장")
# 학습 모델 저장하는 이유 ? 요청때마다 하면 리소스가 너무 낭비
|
cs |
(2) html 소스코드 (일부분)
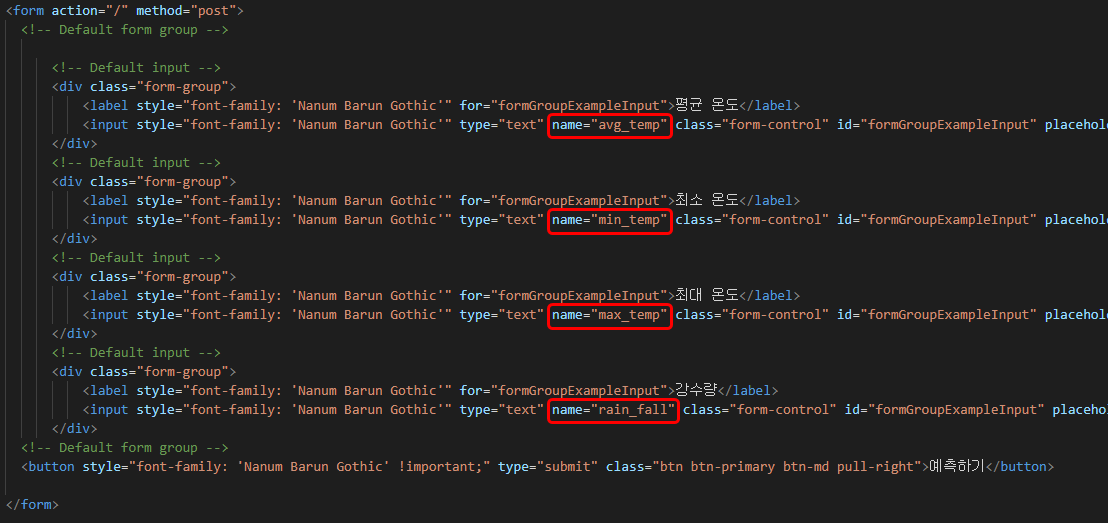

(3) Flask가 포함되어있는 Python 분석 소스코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
#utf-8
from flask import Flask, render_template, request
import tensorflow.compat.v1 as tf
import numpy as np
import datetime
#app이라는 플라스크 객체
app = Flask(__name__)
tf.compat.v1.disable_eager_execution()
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 4])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([4,1]),name="weight")
b = tf.Variable(tf.random_normal([1]),name="bias")
hypothesis = tf.matmul(X, W) + b #가설부분
#저장된 모델 가져오기
saver = tf.train.Saver()
model = tf.compat.v1.global_variables_initializer()
sess = tf.Session()
sess.run(model)
save_path = "./model/save.cpkt"
saver.restore(sess, save_path)
#기본 경로 설정
@app.route("/", methods=['GET','POST']) #기본 경로에 접속시 get, post 메소드 사용 가능하도록
def index():
if request.method == 'GET':
return render_template('index.html') #get 시 index.html 보여주기
if request.method == 'POST':
avg_temp = float(request.form['avg_temp'])
min_temp = float(request.form['min_temp'])
max_temp = float(request.form['max_temp'])
rain_fall = float(request.form['rain_fall'])
price=0
#사용자가 가져온 데이터 2차원으로 만들고
data = ((avg_temp, min_temp, max_temp, rain_fall), )
arr = np.array(data, dtype=np.float32)
x_data = arr[0:4]
dict = sess.run(hypothesis, feed_dict={X: x_data}) #가설에다가 적용 후
price = dict[0] #결과값을 출력
return render_template('index.html',price=price) #price라는 변수에 값 부여
if __name__ == '__main__': #메인 함수로 지정함으로써 웹서버 구동
app.run(debug=True)
|
cs |
Flask 소스코드 : 7-8, 29-38, 50-54
Flask 소스코드를 제외한 다른 Python 소스는 위의 '(1) python 소스'와 비슷하다.
6. 결과 화면 (웹)
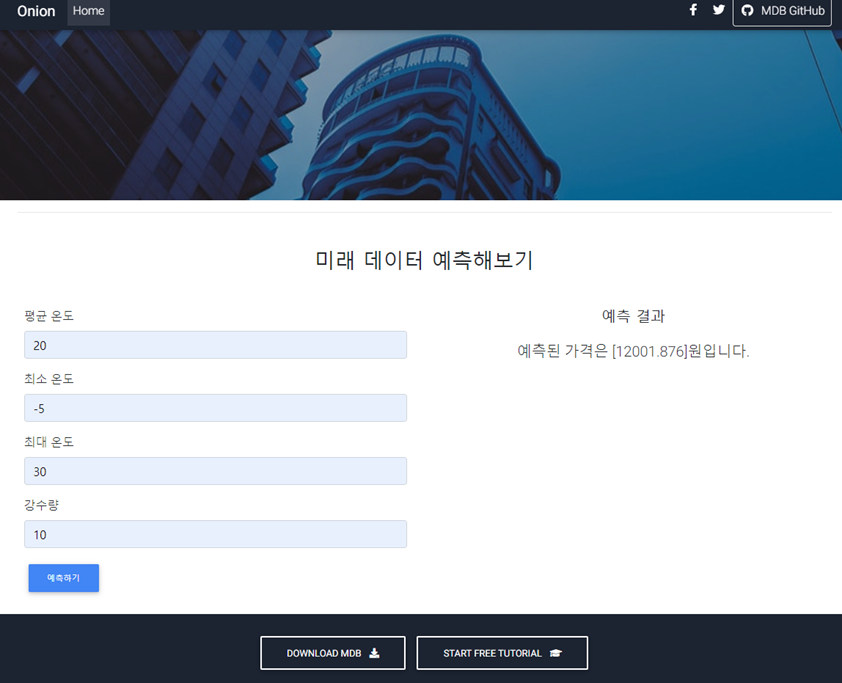
7. 결론
→ 사용자가 접속할 때마다 처음부터 분석이 아닌 체크포인트 이후만 분석을 하기 때문에 시간 절약 됨
→ Flask를 처음 접하는 사람이 단 기간에 공부하기에 너무 좋음 : )
'웹 > Flask' 카테고리의 다른 글
| [Flask] API를 연동한 Flask 웹서비스 - AWS (0) | 2021.05.04 |
|---|---|
| [Flask] API를 연동한 Flask 웹서비스 - crontab (0) | 2021.04.29 |
| [Flask] API를 연동한 Flask 웹서비스 - html (0) | 2021.04.29 |
| [Flask] API를 연동한 Flask 웹서비스 - crawling (0) | 2021.04.29 |
| [Flask] API를 연동한 Flask 웹서비스 - 구조 (0) | 2021.04.29 |