1. ElasticSearch vs RDB
| ElasticSearch | RDB |
| Get | Select |
| Put | Update |
| Post | Insert |
| Delete | Delete |
2. 인덱스
1) 인덱스 있나 없나 확인
curl -XGET http://localhost:9200/classes?pretty
2) 인덱스 없으면 데이터 생성
curl -XPUT http://localhost:9200/classes

2) 인덱스 없으면 인덱스 생성
curl -XPUT http://localhost:9200/classes
3) 인덱스 지우기
curl -XDELETE http://localhost:9200/classes
4) 인덱스 조회

3. Document
1) Document 생성 및 조회
curl -XPOST http://localhost:9200/classes/class/1/ -d '{~~~~~~}'
인덱스명 : classes , 타입명 : class , id : 1

2) Document 생성 및 조회 (파일을 활용)
curl -XPOST http://localhost:9200/classes/class/1/ -d @test.json
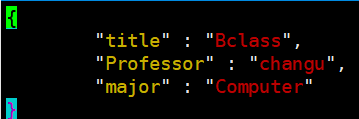
*에러 발생 -> 해결

수정 전 : curl -XPOST http://localhost:9200/classes/class/1/ -d @test.json
수정 후 : curl -XPOST http://localhost:9200/classes/class/1/ -d @test.json -H 'Content-Type: application/json'

3) Document 수정
curl -XPOST http://localhost:9200/classes/class/1/_update?pretty -d '{"doc":{"unit":1}}'


+ 추가) 다른 변경 방법


* sarding : 처리 성능 향상을 위해 index를 분산하여 저장하는 것
3) Document 여러개 입력


참고 : YouTube ( Minsuk Heo 허민석 )
'빅데이터 > 엘라스틱서치' 카테고리의 다른 글
| [ElasticSearch] 엘라스틱서치 구축 (0) | 2020.08.20 |
|---|





